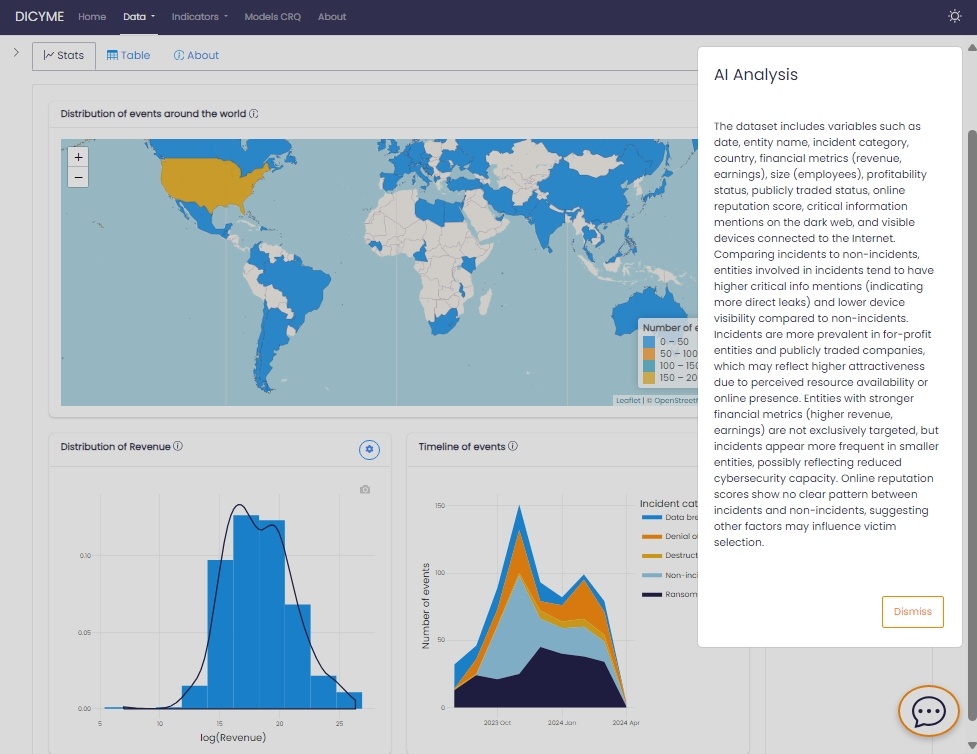
El proyecto DICYME aprovecha la inteligencia artificial para mejorar la evaluación del riesgo cibernético mediante el uso de Modelos de Lenguaje de Gran Escala (LLMs). Estos modelos proporcionan información automatizada y explicaciones que ayudan a los usuarios a interpretar datos complejos de ciberseguridad. Para garantizar eficiencia, seguridad y fiabilidad, DICYME ha desarrollado una infraestructura local robusta que permite procesar y generar respuestas sin depender de servicios externos.
Arquitectura del sistema
Para integrar los LLMs en la plataforma sin comprometer la privacidad de los datos, DICYME emplea una infraestructura autoalojada dedicada. La configuración consta de:
-
Ejecución en Ollama: El modelo seleccionado se ejecuta localmente en un servidor dedicado, asegurando un control total sobre el procesamiento y eliminando la dependencia de APIs externas o servicios en la nube.
-
Entorno de contenedores: Un contenedor Docker aloja una aplicación en Flask (Python), desplegada a través de un servidor WSGI, lo que garantiza escalabilidad y mantenimiento.
-
Integración con base de datos local: Una instancia de MongoDB almacena datos relevantes del proyecto, permitiendo al sistema recuperar información contextual de manera dinámica en cada solicitud.
Flujo de ejecución de consultas
Cuando un usuario realiza una solicitud, el sistema sigue un proceso estructurado en múltiples pasos para garantizar el rendimiento óptimo del modelo y la calidad de las respuestas:
-
Recepción de la solicitud: La API recopila las entradas del usuario y cualquier dato precomputado relevante de la aplicación web de DICYME.
-
Enriquecimiento de la consulta: La API consulta la base de datos MongoDB para obtener información adicional necesaria, asegurando que el modelo tenga un contexto completo.
-
Preprocesamiento de datos: Los datos recuperados se preprocesan junto con las entradas recibidas de la aplicación para garantizar que la respuesta refleja adecuadamente lo que el usuario está viendo, aplicando cualquier filtro seleccionado.
-
Construcción del prompt: Se genera un prompt adaptado, incorporando tanto los datos del usuario como los datos preprocesados, en un formato estructurado y optimizado para el procesamiento del modelo.
-
Manejo de consultas fragmentadas (si aplica): Para solicitudes complejas que requieren análisis en profundidad, el sistema divide la consulta en partes más pequeñas, permitiendo que el modelo las procese de forma independiente antes de combinar los resultados. Esta técnica mejora la calidad del razonamiento al reducir la sobrecarga de contexto y mejorar el enfoque en subconjuntos de datos.
-
Ejecución del modelo: El prompt construido se envía al modelo alojado localmente, garantizando una inferencia de alto rendimiento en un entorno controlado.
-
Agregación y refinamiento de la respuesta: Si la solicitud fue fragmentada, las respuestas individuales se sintetizan en una respuesta final coherente.
-
Devolución de la respuesta: La salida final refinada se envía de vuelta a la aplicación web para su visualización por el usuario.

Pruebas y evaluación
Se han realizado pruebas exhaustivas con diferentes LLMs y arquitecturas para determinar el mejor enfoque en la generación de explicaciones relacionadas con ciberseguridad. Algunas de las principales evaluaciones incluyen:
-
Pruebas con Llama 3.2 y DeepSeek: Se evaluó su capacidad para generar respuestas precisas y contextualizadas en el entorno de DICYME. Actualmente,
deepseek-r1:32bes el preferido debido a sus sólidas capacidades de razonamiento, particularmente en el manejo de datos estructurados y la resolución de problemas en múltiples pasos. -
Exploración de arquitecturas alternativas, incluyendo el paquete
{ellmer}en R, que se consideró como una herramienta complementaria potencial. Sin embargo, sus capacidades fueron inferiores a las obtenidas con Python y Flask.
Trabajo futuro
El proyecto DICYME continúa refinando su uso de LLMs con mejoras en curso, incluyendo:
-
Optimización de la ingeniería de prompts para mejorar aún más la relevancia y precisión de las respuestas.
-
Exploración de modelos más ligeros para una ejecución más rápida en entornos con recursos limitados.
-
Mejora en la estructuración de respuestas, especialmente en consultas de múltiples pasos que requieren la síntesis de respuestas fragmentadas.
-
Expansión de estrategias multi-modelo, aprovechando potencialmente LLMs especializados para diferentes tareas.
Al integrar completamente los LLMs en su marco de evaluación de riesgos, DICYME permite a los usuarios de la aplicación web acceder a información avanzada impulsada por inteligencia artificial, manteniendo un control absoluto sobre la privacidad de los datos y la ejecución del modelo.