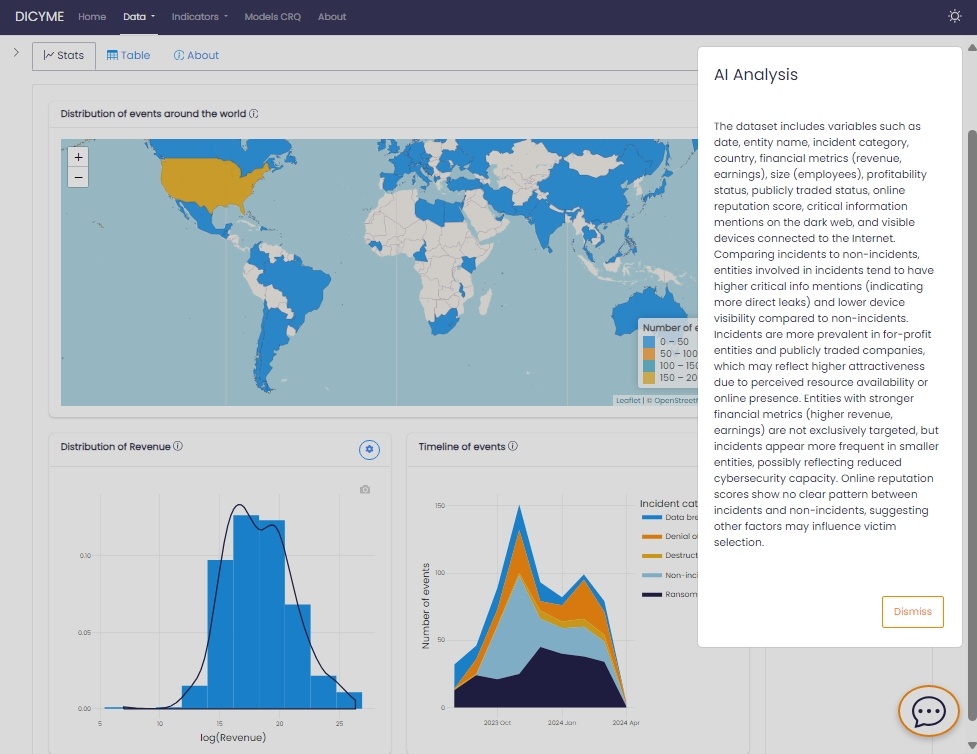
The DICYME project leverages artificial intelligence to enhance cybersecurity risk assessment through the use of Large Language Models (LLMs). These models provide automated insights and explanations to help users interpret complex cybersecurity data. To ensure efficiency, security, and reliability, DICYME has developed a robust local infrastructure to process and generate responses without reliance on external services.
System architecture
To seamlessly integrate LLMs into the platform while preserving data privacy, DICYME employs a dedicated self-hosted infrastructure. The setup consists of:
-
Ollama runtime: The selected model runs locally on a dedicated server, ensuring full control over processing and eliminating reliance on external APIs or cloud-based services.
-
Containerized environment: A Docker container hosts a Flask Python application, deployed via a WSGI server, ensuring scalability and maintainability.
-
Local database integration: A MongoDB instance stores relevant project data, allowing the system to retrieve contextual information dynamically for each request.
Query execution pipeline
When a user request is made, the system follows a structured multi-step process to ensure optimal model performance and response quality:
-
Receiving the request: The API collects inputs and any relevant precomputed data from the DICYME web app.
-
Query enrichment: The API queries the MongoDB database to gather additional necessary information, ensuring the model has a comprehensive context.
-
Prompt construction: A tailored prompt is generated, incorporating both user inputs and retrieved data in a structured format optimized for model processing.
-
Fragmented query handling (if applicable): For complex requests requiring in-depth analysis, the system divides the query into smaller parts, allowing the model to process them independently before merging the results. This technique enhances reasoning quality by reducing context overflow and improving focus on individual data subsets.
-
Model execution: The constructed prompt is sent to the locally hosted model, ensuring high-performance inference in a controlled environment.
-
Response aggregation and refinement: If the request is fragmented, responses from individual queries are synthesized into a coherent final answer.
-
Returning the response: The refined output is sent back to the web application for display to the user.

Testing and Evaluation
Extensive testing has been conducted with different LLMs and architectures to determine the best approach for cybersecurity-related explanations. Some key experiments include:
-
Llama 3.2 and DeepSeek evaluations: These models were assessed for their ability to generate accurate, context-aware responses within the DICYME environment. Currently,
deepseek-r1:32bis preferred due to its strong reasoning capabilities, particularly in handling structured cybersecurity data and multi-step problem-solving. -
Alternative architectures, including the
{ellmer}R package, has also been explored as a potential supplementary tool. However, its capabilities are poorer than those achieved with Python and Flask.
Future work
The DICYME project continues to refine its use of LLMs with ongoing improvements, including:
-
Optimizing prompt engineering to further enhance response relevance and accuracy.
-
Exploring lighter models for faster execution in constrained environments.
-
Enhancing response structuring, particularly in multi-step queries requiring synthesis across fragmented responses.
-
Expanding multi-model strategies, potentially leveraging specialized LLMs for different tasks.
By fully integrating LLMs into its risk assessment framework, DICYME empowers web app users with advanced AI-driven insights while maintaining complete control over data privacy and model execution.